Self-Supervised Visuotactile Representation Learning for Manipulation
Project Details
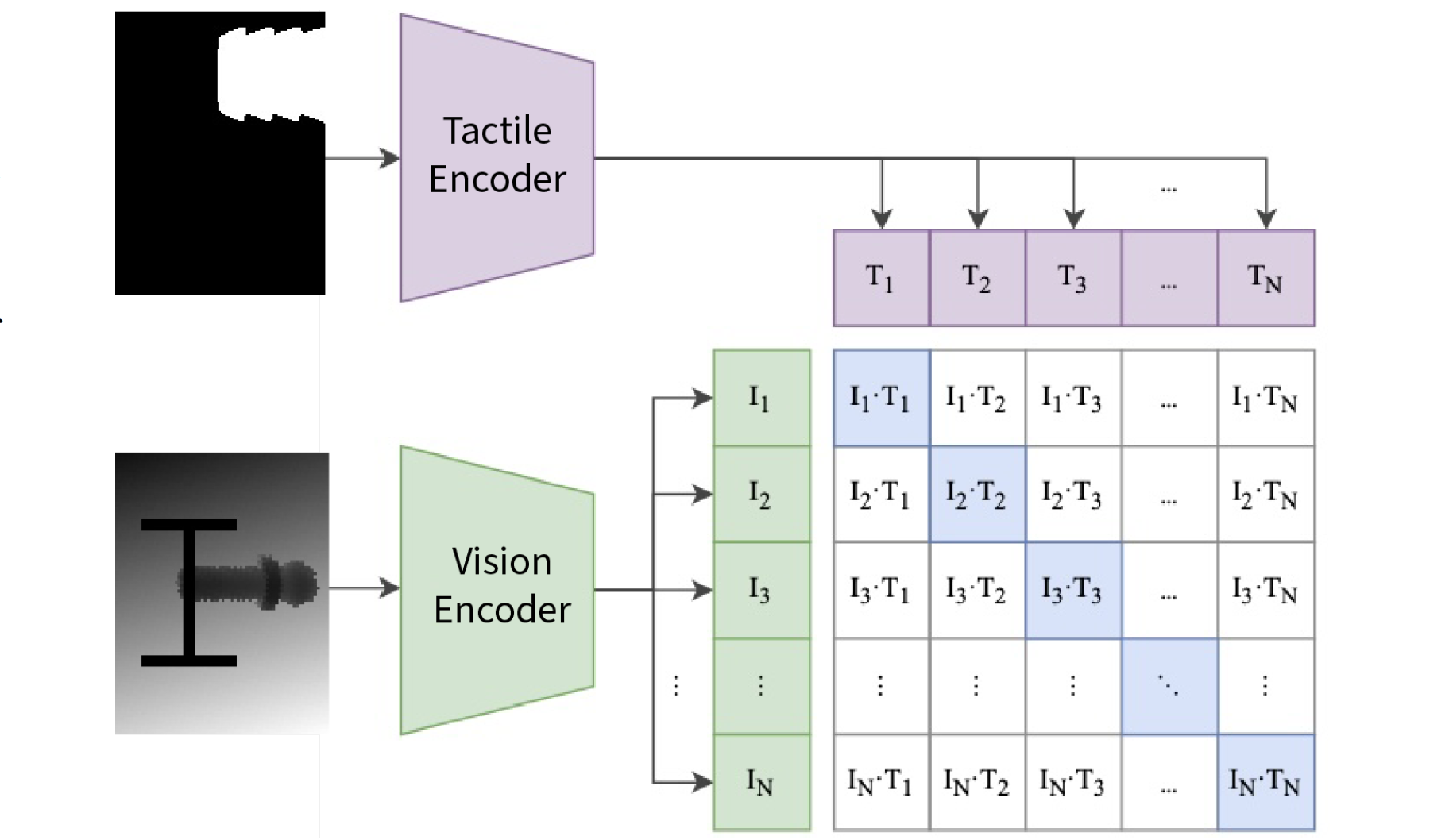
The ability to integrate complementary information from vision and touch is a long-standing goal in robotic manipulation. While vision provides global information about an object's position and orientation, touch provides local signals of contact geometry and forces, which are important to supervise contact-rich interactions, especially in the presence of visual occlusions. In this work, we combine these modalities for two different robotics-minded goals: object classification and joint representation learning. To learn a joint representation, the visual and tactile images are embedded into a shared latent space using a cross-modal contrastive loss trained in a self-supervised manner. We implement and compare each network architecture with ResNets and Vision Transformers.
- Read more: Final Report